去年进博会期间,瑞萨发布了RA8系列芯片。瑞萨说这是行业内首款基于Arm Cortex-M85的MCU。当时瑞萨向我们详细介绍了这颗MCU,着重强调借助于Arm Helium技术,RA8系列的DSP, AI/ML性能获得大幅提升。nosesmc
原本《国际电子商情》4月刊封面故事相关智慧城市主题撰写,我们采访了瑞萨——其时撰写计划变更致采访内容被搁置。最近笔者整理这份来自瑞萨的采访问卷,发现瑞萨多番提到了智慧城市对于AI技术的需求。王均峰(瑞萨电子全球系统及解决方案事业部总监)列举瑞萨有关智慧城市领域内的产品,涵盖通信(如Wi-Fi)、模拟(电源管理等相关)、AI,当然还有瑞萨擅长的解决方案。nosesmc
AI战略部分引起我们的关注,“我们2022年收购Reality AI,且与EdgeCortix建立战略合作关系等,这是我们AI战略执行的体现。”王均峰表示,“我们推出性能达到6.49 CoreMark/MHz的基于Arm Cortex-M85处理器的MCU RA8,是我们对于边缘AI在保证一定算力前提下对实时响应和超低功耗更高要求的反馈。”nosesmc
我们一直都很好奇,MCU作为一种对实时性有要求的控制器,是如何实现边缘AI处理工作的。所以这篇文章,我们期望借着RA8来谈谈Arm Helium技术。这篇文章对于基于MCU做应用开发可能没什么价值,因为Helium的技术实现这部分是工程师完全不需要关心的;但对于芯片技术爱好者而言可能会有收获:一个听起来简单的加速技术,实则是设计层面多维度的考量。nosesmc
先谈谈RA8
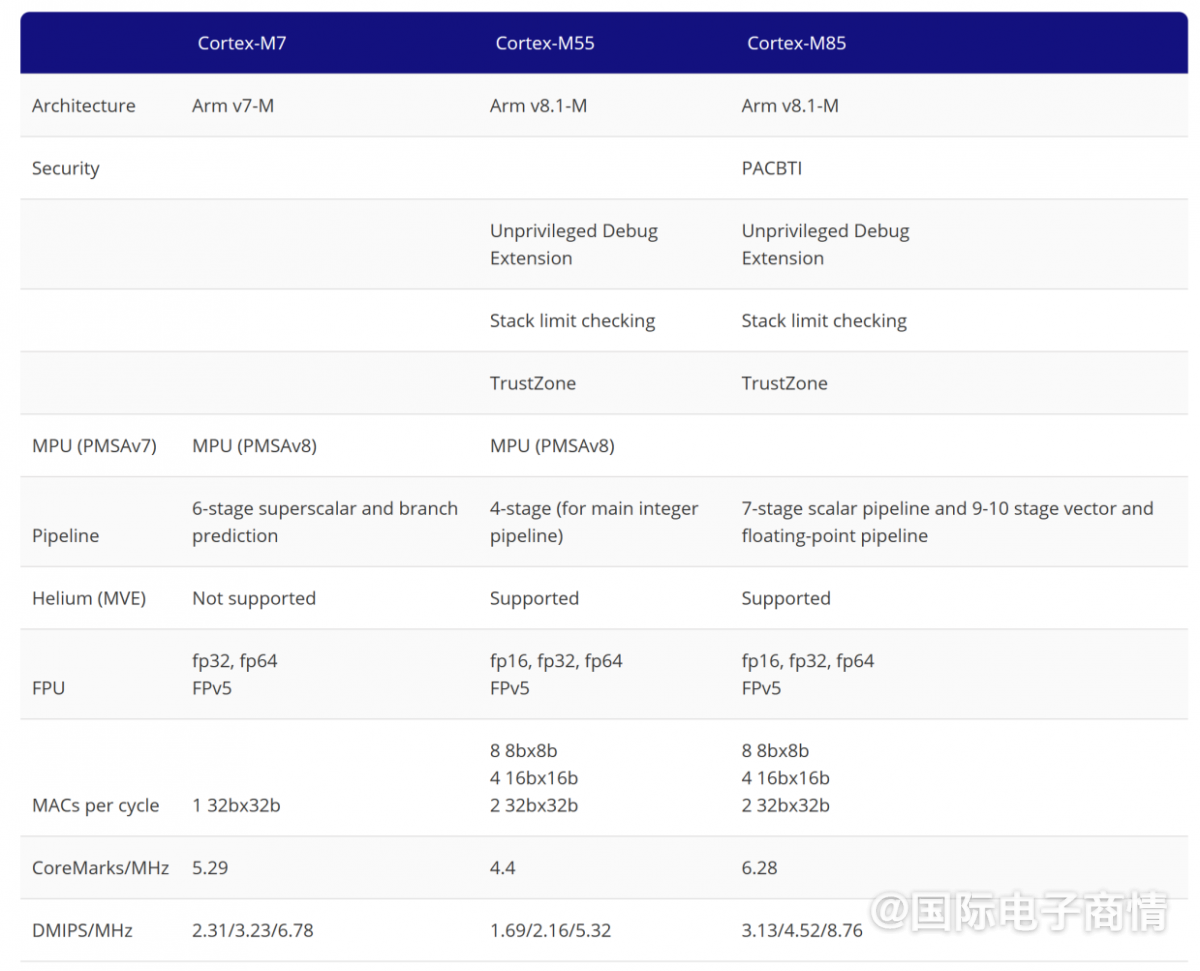
首先还是从高层架构审视一下瑞萨RA8系列MCU。基于Arm Cortex-M85决定了RA8在MCU里面是属于性能彪悍的那一波。此前我们采访瑞萨时,瑞萨将Cortex-M85和Cortex-M7做了性能对比,对比参数涵盖Arm v8.1-M内核架构,TrustZone支持,不同精度浮点数硬件支持及每周期数学性能提升,CoreMarks/MHz。nosesmc
 nosesmc
nosesmc
来源:瑞萨电子nosesmc
当然还有对于Helium的支持。相较M7,M85最大的亮点应该是DSP/ML性能提升4倍,标量性能提升30%。nosesmc
具体到瑞萨RA8M1, 2MB Flash, 1MB SRAM资源也充足;通信接口包括以太网、USB、CAN-FD等主流外设,还有个Octal SPI,可接Octal Flash或HyperRAM。具体的功能安全、信息安全特性此处不再详述,可见下图。nosesmc
 nosesmc
nosesmc
总体来看,这是个很多配置在向MPU靠拢,但开发更容易的产品。瑞萨此前告诉我们,有不少客户都需要此类产品,因为市场上以前是没有同类选择的,以前“就只能选外置flash的MPU方案”,“RA8相当于填补了市场需求的空白。尤其近一年AI火了以后,终端AI的需求越来越强烈。”nosesmc
王均峰在解释瑞萨对AI智慧城市的态度时,提到了技术层面更具体的两个例子。其一是瑞萨对于Reality AI的收购;其二就是推出了RA8。有关前者,Reality AI提供嵌入式AI和TinyML解决方案,用于汽车、工业及消费类产品,“完美适配瑞萨嵌入式处理及物联网产品”,“适用于小型MCU和强大MPU。”基于此,瑞萨也有了更全面的AI解决方案。nosesmc
有关RA8系列MCU,王均峰 用“具有里程碑式的意义” 形容,“标志着高性能微控制器领域的一次重要突破”。除了前文都已经提到的基于Cortex-M85,性能强,他还补充说:“RA8系列MCU针对图形显示和外设功能进行了优化,能够更好地满足楼宇自动化、家用电器、智能家居等领域的需求,特别是在图形显示和语音/视觉多模态AI应用方面。”加上强调安全性,RA8的应用领域还包括消费电子、医疗设备等。nosesmc
Helium和Neon之间
在此前的采访中我们就问过瑞萨,Arm Helium是否是指令级别实现,瑞萨的回答是不只是这样,并且表示开发者和用户并不需要关心这些——“现在的开发流程和以前不一样了”。Arm官网解释中提到,Helium是Arm Cortex-M系列产品的MVE(M-Profile Vector Extension)——一种新的矢量指令集扩展,是Armv8.1-M的可选项,主要是为了机器学习和DSP应用提供性能支持的。nosesmc
Cortex-M55和Cortex-M85是两颗最早支持Helium的处理器,“让小型、低功耗嵌入式系统能够在诸多应用,如音频设备、传感器hub、关键词识别、语音指令控制、功率电子、通信和静态图片处理等领域,解决计算挑战。”nosesmc
Armv8.1-M架构白皮书中提到,Helium和Neon之间有诸多共同之处。对Cortex-A系列熟悉的同学对Neon应该不会陌生。但Arm强调Helium是在小型处理器内实现有效信号处理的全新设计,其中包含了不少新的架构特性,用以加强嵌入式使用场景中的计算性能,兼顾到面积和功耗——所以是“把Neon能力(Cortex-A的SIMD指令)带到了M-Profile架构”。nosesmc
Helium和Neon同样都是128-bit矢量size,用浮点单元的寄存器作为矢量寄存器,另外Helium和Neon都有对应的一些矢量处理指令。nosesmc
但两者的差别在于,Helium在设计理念上主要考虑对现有硬件的最大化利用,用的矢量寄存器也少于Neon;Helium的某些操作会用上矢量寄存器和标量寄存器组中的寄存器;Helium支持的数据类型会更多;此外,Helium还支持诸如循环预测、通路预测(lane predication)、复杂数学和scatter-gather内存访问。nosesmc
 nosesmc
nosesmc
白皮书中列举了Helium新增的一些指令和特性。比如说交错(interleaving)和去交错(de-interleaving)load/store指令;支持证书和浮点矢量复杂值处理的指令;nosesmc
还特别提到lane predication,对于矢量每条lane做条件执行支持的MVE特性——为了达成这项特性,需要专门的寄存器(名为VPR)来保持每条lane的条件;还有大整数支持,引入了大整数处理指令;以及低开销分支扩展,引入了低开销循环和额外的分支指令等。nosesmc
Arm引入Helium的目标是期望用单颗处理器,取代过去部分开发者需要将专用DSP和Cortex-M处理器一起用的方案。这应该也是瑞萨所说填补市场空白的关键。因为这么做可以简化软件开发,也降低了芯片设计的复杂性和成本。另外Cortex-M处理器具备了高度通用性,执行某些通用非DSP负载还是比很多老的DSP更快。nosesmc
应该说Helium技术,以及RA8这样的产品,在嵌入式领域就开发者角度来看是具备了相当吸引力的。nosesmc
关键特性:beatwise
了解到这个程度还是不够的,我们更想搞清楚,Helium在更具体的处理器架构上有哪些变化。Arm工程师在Arm社区更新过系列文章专门谈Helium技术的,起始篇章就是,如果说要提升DSP和ML性能,为什么不直接给Cortex-M加个Neon?其关键还是在于具体实施方案上,Helium和Neon的差异。nosesmc
要有出色的DSP数字信号处理性能,有相当一部分工作应该是喂足够的数据。所以Cortex-A处理器直接从数据cache里拉128bit Neon负载就会显得游刃有余。但Cortex-M不同,cache资源少,主存追求低延迟——将SRAM路径扩展到128bit对于很多系统而言首先就是不可接受的。另外,MAC指令所需的乘法器占用的芯片面积不小,要在面积敏感的Cortex-M处理器上做4x 32bit乘法器相当的不靠谱。nosesmc
这些都决定了Helium的设计必须是对资源的物尽其用,把资源用在刀刃上,尤其存储、乘法之类的用了就要保证每周期执行的高效。像Cortex-M7的方案是,通过双发射矢量负载(矢量MAC)来确保资源占用;但Helium的目标是要在不同的性能水平上增加DSP性能,而不仅仅是面向M7这样的高端处理器。所以Arm想到了古早的一些技术。nosesmc
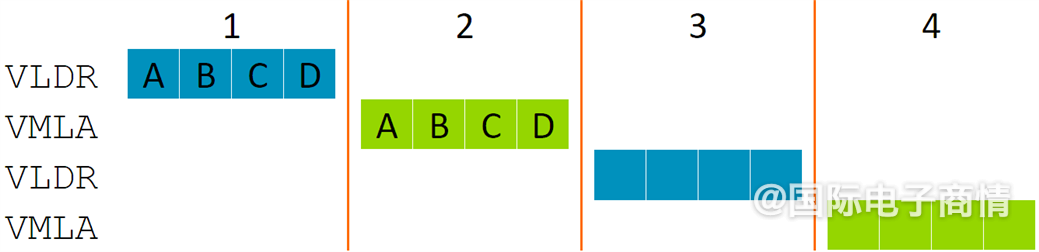 nosesmc
nosesmc
上面这张图展示了VLDR矢量加载和VMLA矢量MAC指令执行序列要超过4个时钟周期,还要求通向存储128bit位宽的通路,4个MAC block,其中有俩一半时间还是闲置的。这张图中,每条128bit宽度的指令切成了4等分,MVE架构称其为beat。这些beats总是做32bit计算,可以是1 x32-bit MAC,也可以是4 x8bit MAC。nosesmc
 nosesmc
nosesmc
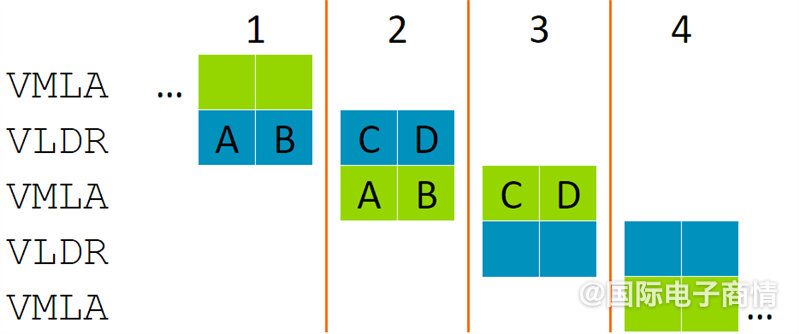
考虑到load和MAC执行单元是分开的,这些beats的执行过程其实是可以重叠的。在C, D beat执行VLDR的时候,A, B就可以执行VMLA。如此一来性能就能达到128bit数据通路处理器的水平,但却只需要一半的硬件资源。nosesmc
基于这种叫做“beatwise”的执行概念,32bit数据路径的处理器,也能处理上述相同指令。Arm的说法是如此实现了单发射标量处理器的性能翻番(8个周期以8 x32bit值加载和执行MAC),却完全不需要考虑双发射标量指令的面积和功耗惩罚问题。MVE支持最多每周期4个beat实施方案,在某些情况下这种beatwise的执行方式就类似于传统的SIMD。nosesmc
不过beatwise执行也诞生了一些问题,比如说多个部分执行的指令同时进行,打断和错误处理就会很复杂;再比如如果一个指令跨beat,则仍然需要考虑空闲时间或者stall等待的问题;另外要确保执行上的重叠,对应的每条指令都应当操作128bit数据...这些挑战都需要在设计时做考量。具体的受限于篇幅,就不多做解释了。nosesmc
但总的来说,这种beatwise执行方案,是MVE达成PPA平衡的基础。nosesmc
配合beatwise的其他特性
有关Helium还有几个配套关键技术是值得一谈的。比如前面提到每条指令应当尽可能操作等长数据:DSP处理是需要面向不同的数据格式的。就像图像数据,一般是以交错的红、绿、蓝,外加alpha通道像素值做存储的。nosesmc
为了对计算做矢量化,需要让所有的红色像素为一个矢量,所有绿色像素为另一个矢量等等…在Neon结构里,VLD4/VST4指令是用于执行这类转换的。还有像是VST2指令,用于交错立体声音频的左右两个通道。这类指令支持8-32bit的不同尺寸。nosesmc
前面我们提到了MVE的beatwise执行,是让存储和ALU操作重叠进行。为了确保这种重叠,每条指令都应该操作128bit数据。此时VST4这样的指令store数据位数过多,会让ALU长时间处在空闲状态。nosesmc
MVE的方案是将store再切分成块,与ALU操作达成平衡,每个块都仅存储128bit数据。512bit的store,也就是4-way交错,MVE有4条指令VST40, VST41, VST42, VST43。nosesmc
不过这么做还是会带来一些问题:比如说这4条指令存储不同的通道,对8bit像素数据而言意味着每条指令可能存储了非连续的数据,这样的访问模式对于存储子系统而言会很悲剧。以及和其他矢量指令合作,寄存器堆port需要设定为访问行,而不是列等。Arm在blog文章里具体探讨了此类问题的解决方案。nosesmc
 nosesmc
nosesmc
此外,数据访问和存储也是Helium技术关注的重点之一。毕竟在beatwise大前提下,4-beat矢量架构需要考虑如何处理数据load为矢量及存储操作。所以要进行“连续load”操作,针对每个beat,从标量寄存器中指定的base地址开始,连续访问内存。无论目标数据类型如何,这都将有效利用总线带宽。nosesmc
有关数据存取,Helium引入了所谓的size变化内存操作(size-changing memory operations):数据可存储为面向每个beat的8, 16或32bit单次访问,基于置0或者符号扩展来达到预期的数据类型。而对于store,数据也可以缩减到预期的size。配套的load和store指令覆盖了比较丰富的寻址模式,特性方面涵盖pre或者post-incrementing和指针回写支持,在绝大部分情况下也就不需要进行单独的指针操作。nosesmc
最后设计上还考虑并行度瓶颈问题。Arm在blog中列举了内存复制代码的一个例子:具体是循环迭代次数递减,循环过程中,条件分支回到循环开头占到了指令的50%。许多小型Cortex-M处理器是没有分支预测器的,受制于分支惩罚,runtime开销实际上就超过了这50%。Helium也考量了对应的解决方案——和Armv8.1-M引入低开销循环和新增条件指令应该有关,相关因素在代码层面比较具体,包括各类方法的利弊,有兴趣的同学还是建议去读一读Arm的blog。nosesmc
本文最后再给出瑞萨就应用层面的一些信息。毕竟从芯片设计企业的角度,还是更能看出技术效果的。瑞萨在去年4月的两篇blog中,给出了有关Cortex-M85和Helium-MVE的阐释和实测。nosesmc
瑞萨也认为Helium是用于替代低端到中端DSP核心的方案,“8个128bit矢量寄存器,针对不同的应用支持广泛的矢量数据类型”,“特性诸如重叠的pipeline,加强的分支预测,和循环优化,都为性能提升有助益”,“加强的存储访问指令和复杂值处理支持,令Helium成为Cortex-M85的强有力扩展。”nosesmc
 nosesmc
nosesmc
这段话基本也总结了我们整篇文章提到的有关Helium的关键特性。瑞萨在blog中列举了两个demo——这里我们谈其中的一个,进博会上瑞萨展示过:人物识别AI套件,基于RA8D1:展示的是检测摄像头拍到的人,据说检测距离能达到20米,支持180°摄像头,各种光线和环境下都没问题。nosesmc
这个demo是瑞萨和PlumerAI合作完成的。演示基于TinyML模型——当时瑞萨的现场工作人员告诉我们,模型训练超过3200万张图片。要知道这个演示完全没有用到任何的加速器,单凭藉MCU完成。这就属于典型的低成本、低功耗AI解决方案了。nosesmc
 nosesmc
nosesmc
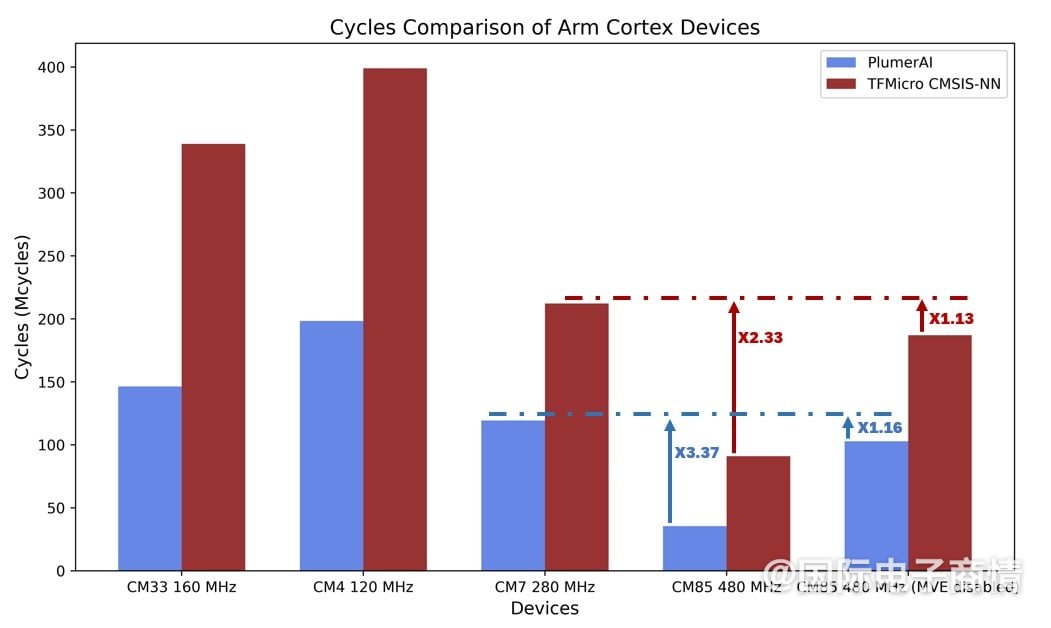
上面这张图是瑞萨给出Cortex-M85与其他Cortex-M核的性能比较,柱状图中的蓝色柱子表示用PlumerAI的推理引擎来跑,红色表示用TensorFlow Lite for Microcontrollers来跑。另外最右边的两列CM85,分别表示启用Helium MVE和不用Helium MVE。M85相比M7,此处性能差距最大有3.37倍。更快的推理速度,自然意味着CPU可以更早回到睡眠模式,实现总体的低能耗。nosesmc
当然在嵌入式应用中,若有更高AI性能需求,王均峰也谈到还是可以用AI加速器配合MCU使用,瑞萨也提供AI SDK,其中有各种常见AI算法和工具。不过Helium技术,及RA8系列MCU的出现,的确还是为嵌入式应用提供了更多的可能性;也是现如今我们谈AI everywhere的实现组成部分之一。nosesmc
责编:Elaine










