国际电子商情27日讯 过去一周,来自中国的DeepSeek R1模型“搅动”整个海外AI圈。pSuesmc
- Meta内部已经进入恐慌模式,工程师们开始连夜尝试复制DeepSeek的成果;
- 著名投资者A16z的创始人马克·安德森称赞DeepSeek R1为“最令人惊叹的突破”,并称其为“给世界的一份礼物”;
- Mistral AI董事会成员Anjney Midha指出:“几乎一夜之间,DeepSeek-R1成为美国顶尖大学研究人员的首选模型”;
- 美国AI数据服务公司Scale AI创始人Alexander Wang直言:“DeepSeek-V3是中国科技界带给美国的苦涩教训”……
什么是DeepSeek?它为何在全球范围内引起轰动?与DeepSeek相关的公司有哪些?pSuesmc
让硅谷震惊的中国大模型——DeepSeek
公开资料显示,中国AI初创公司深度求索(DeepSeek)成立于2023年5月,是一家大模型创业公司。仅成立半年后,DeepSeek就推出了免费商用、完全开源的代码大模型DeepSeek Coder。2024年5月,该公司发布开源模型DeepSeek V2,将推理成本降低近百倍,一跃成名。pSuesmc
2024年12月27日,DeepSeek推出了开源模型DeepSeek-V3。pSuesmc
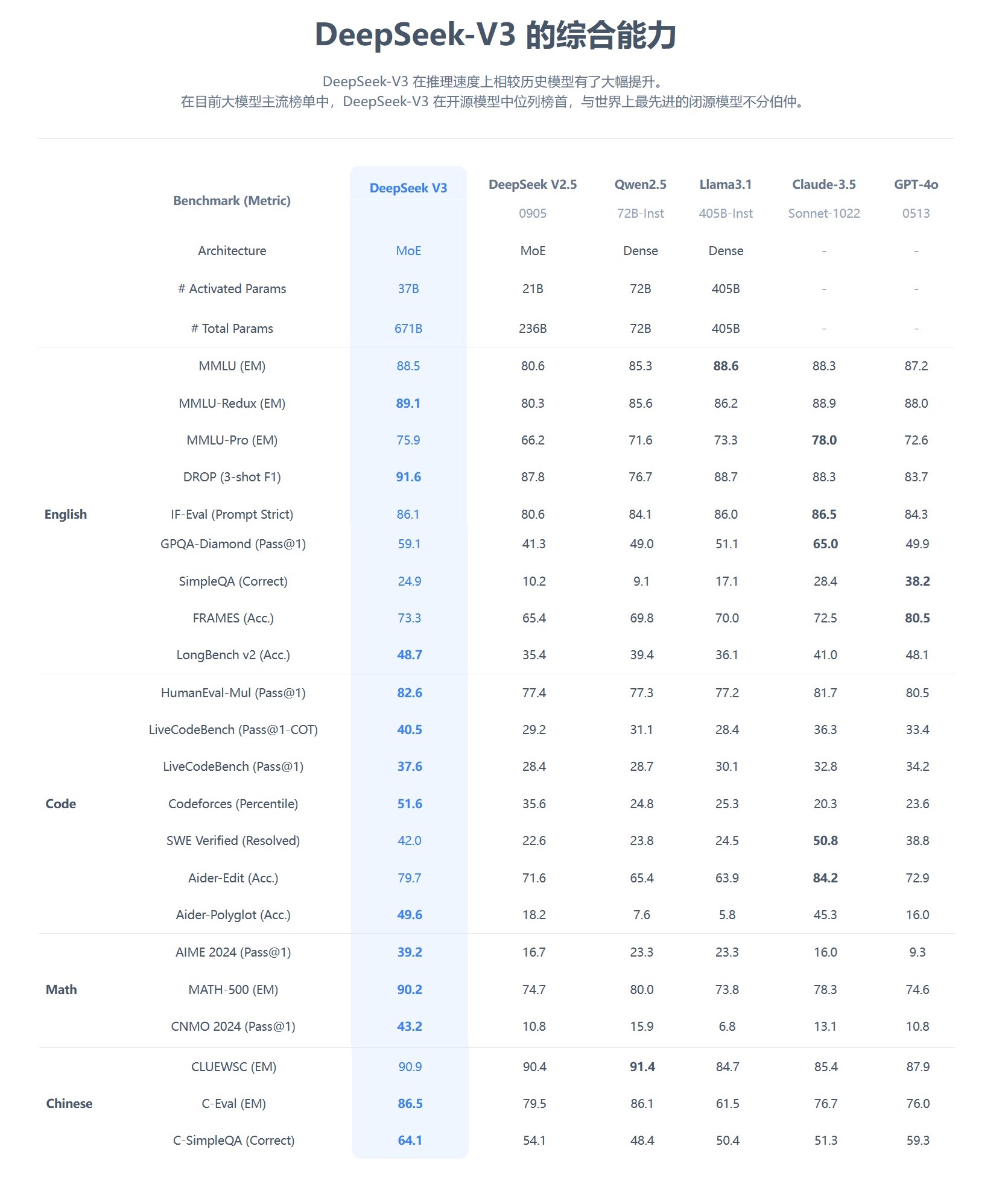
这款模型在多项基准测试表现优异,超越业内主流顶尖模型,特别是在知识问答、长文本处理、代码生成和数学能力等方面。例如,在MMLU、GPQA等知识类任务中,DeepSeek-V3的表现接近国际顶尖模型Claude-3.5-Sonnet。pSuesmc
在数学能力方面,更是在AIME 2024和CNMO 2024等测试中创造了新的记录,超越所有已知的开源和闭源模型。同时,其生成速度较上代提升了200%,达到60TPS,大幅改善了用户体验。pSuesmc
当时,在国外大模型排名Arena上,DeepSeek-V3在所有模型中排名第七,在开源模型排第一。而且,DeepSeek-V3是全球前十中性价比最高的模型。pSuesmc
 pSuesmc
pSuesmc
意料之外的是,在DeepSeek-V3发布不到1个月之后,更“炸街”的DeepSeek-R1来了!pSuesmc
2025年1月20日,DeepSeek正式开源R1推理模型。性能对齐OpenAI-o1,正式版DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。pSuesmc
目前普遍认为,DeepSeek的R1发布标志着推理模型研究的重要转折点,而在此之前推理模型一直是工业研究的重要领域,但缺乏一篇开创性的论文,就像AlphaGo使用强化学习下了无数盘围棋并优化其策略以获胜一样,DeepSeek正在使用相同的方法来提升其能力,因此2025年可能会成为强化学习的元年。pSuesmc
1月24日,在国外大模型排名Arena上,DeepSeek-R1基准测试已经升至全类别大模型第三,其中在风格控制类模型(StyleCtrl)分类中与OpenAI o1并列第一。而其竞技场得分达到1357分,略超OpenAI o1的1352分。pSuesmc
AI界的“拼多多”?
为何DeepSeek火爆出圈?一方面,它以较低的训练成本实现了媲美OpenAI o1性能的效果,诠释了中国在工程能力和规模创新上的优势;另一方面,它也秉持开源精神,热衷分享技术细节。pSuesmc
值得注意的是,据DeepSeek发布的技术报告显示,DeepSeek-R1的训练费用仅为OpenAI最新大模型的三十分之一。pSuesmc
DeepSeek-V3在仅使用2048块H800 GPU的情况下,完成了6710亿参数模型的训练,成本仅为557.6万美元,远低于其他顶级模型的训练成本。pSuesmc
作为参照,斯坦福大学和Epoch AI的研究人员去年年中发表了一项研究表明,到2027年,最大型的模型的训练成本将超过10亿美元。另外,第三方研究公司Gartner研究预测显示,到2028年Google、Microsoft和AWS等超大规模企业仅在AI服务器上的支出就将高达5000亿美元。pSuesmc
因此,不少业者认为,DeepSeek的低成本意味着,大模型对算力投入的需求可能会从训练侧向推理侧倾斜,即未来对推理算力的需求将成为主要驱动力。而英伟达等硬件商的传统优势更多集中在训练侧,这可能会对其市场地位和战略布局产生影响。pSuesmc
DeepSeek的另一个显著优势是“开源”。pSuesmc
在开源策略上,R1采用MIT License,给予用户最大程度的使用自由,支持模型蒸馏,可将推理能力蒸馏到更小的模型,如32B和70B模型在多项能力上实现了对标o1-mini的效果,开源力度甚至超越了此前一直被诟病的Meta。pSuesmc
Meta首席AI科学家Yann Lecun评价称,DeepSeek-R1面世与其说意味着中国公司在AI领域正在超越美国公司,不如说意味着开源大模型正在超越闭源。pSuesmc
1月22日,美国媒体Business Insider报道称,DeepSeek-R1模型秉承开放精神,完全开源,为美国AI玩家带来了麻烦。开源的先进AI可能挑战那些试图通过出售技术赚取巨额利润的公司。pSuesmc
DeepSeek的关联公司
据不完全统计,目前DeepSeek的关联公司涵盖四类:股权关联方、算力基础设施供应商、垂直领域合作方、业务协同方。pSuesmc
(1)股权关联方pSuesmc
每日互动:幻方量化(Deepseek母公司)二股东,为DeepSeek提供海量用户行为语料数据等。pSuesmc
浙江东方:通过旗下杭州东方嘉富基金参投Deepseek天使轮。pSuesmc
华金资本:珠海国资旗下投资平台间接参与DeepSeekPre-A轮融资。pSuesmc
(2)算力基础设施供应商pSuesmc
中科曙光:承建DeepSeek杭州训练中心液冷系统。pSuesmc
浪潮信息:为Deepseek北京亦庄智算中心提供AI服务器集群及英伟达H800+自研AIStation管理平台。pSuesmc
润泽科技:廊坊数据中心为Deepseek提供3000+机柜资源。pSuesmc
航锦科技:旗下超擎数智为Deepseek提供光模块和交换机。pSuesmc
(3)垂直领域合作方pSuesmc
科大讯飞:在教育领域接入了DeepSeek-Math模型,并联合推出了AI数学辅导应用“星火助学”。pSuesmc
拓尔思:与Deepseek联合开发金融奥情大模型,已在中信证券等机构部署智能研报生成系统。pSuesmc
金山办公:WPS智能写作接入DeepSeek-Writer API,公文生成效率提升3倍,错误率下降90%。pSuesmc
卓创资讯:与幻方量化在金融语料库方面存在合作,其数据资源或用于Deepseek模型的训练和优化。pSuesmc
(4)业务协同方pSuesmc
并行科技:为DeepSeek提供多种计算技术手段,显著提升其计算能力。pSuesmc
竞业达:与DeepSeek大模型对接中。pSuesmc
可见,随着DeepSeek、Minimax等中国公司在AI领域的崛起,全球AI竟争格局正在发生微妙变化。如果中国公司能够以更低的成本实现同等或更好的性能开源大模型,海外开源和闭源模型或都受到挑战。此外应用端在字节豆包带动下持续对商业化场景展开探索,中国AI公司和开源模型或将持续推动大模型产业和相关AI应用的升级。pSuesmc
责编:Momoz
 扫码分享到好友
扫码分享到好友


