2025年,中美自动驾驶芯片平分天下


与PC和智能手机不同,汽车是科技的集大成者,将电子行业过去几十年发展积累下来的技术,包括应用数据平台、基础计算平台、电子电气架构、成熟可靠的零部件、软件等完全综合起来,这对智能化底座和芯片提出了越来越高的要求....
2022秋季GTC大会上,芯片巨头英伟达(NVIDIA)发布了单颗算力达到2000TFLOPS的全新车载芯片“DRIVE Thor”,此前发布的自动驾驶芯片DRIVE Atlan SoC将不再上市,且立即生效。要知道,DRIVE Atlan在英伟达内部一度被称之为“技术的奇迹”,单颗算力为1000TFLOPS,原本预定2024年上市。Iehesmc
2000T是个什么概念呢?简单来说,是Mobileye EyeQ4的800倍,小鹏P5使用的英伟达Xavier(30T)的67倍,特斯拉FSD(144T)的14倍,当前主流的英伟达Orin(254T)的8倍。目前,蔚来搭载的由4颗Orin组成的车载NIO ADAM平台算力一共是1016T,一颗Thor就几乎等于两辆蔚来的总算力。Iehesmc
与Atlan一样,Thor的设计初衷也是用于处理自动驾驶汽车的所有计算需求。请记住,是所有——从信息娱乐系统和传感器融合到实际的自动驾驶算法本身,目标是用一台可以完成所有工作的计算机取代目前汽车内的独立计算机。套用英伟达创始人兼首席执行官黄仁勋的话,“这颗芯片就是为汽车的中央计算架构而生”。 Iehesmc
中国吉利公司旗下的极氪品牌已宣布将在下一代智能电动汽车上搭载DRIVE Thor,并于2025年初开始生产。而眼下,英伟达生态系统中的中国用户还包括蔚来、威马、理想、小鹏、比亚迪、百度Apollo、上汽智己、元戎启行、云骥智行、悠跑科技、文远知行、小马智行、图森未来等一众企业。Iehesmc
国产芯片上车,2025年为限
“我相信未来在智能驾驶领域,中美会成为最主要的博弈双方。“黑芝麻智能首席市场营销官杨宇欣日前在“黑芝麻媒体技术开放日”上表示,得益于中国车企在汽车产业中扮演的重要角色,2025年后,在中央计算架构到来时,如果中国企业做的好,有望在智能汽车领域跟美国企业在细分赛道平分天下。Iehesmc
 Iehesmc
Iehesmc
黑芝麻智能首席市场营销官杨宇欣Iehesmc
第三方机构的数据显示,以2025年为节点,之前更多以L2到L3级别的人机共驾为主,之后,L2级别以上的自动驾驶技术渗透率将超过25%。伴随智能新能源车的发展和电子电气架构的演进,不但智能驾驶SoC芯片的市场容量将超过百亿美金,软件、算法、其他周边芯片也都有非常多的机会,这是中国汽车产业上游的机会。Iehesmc
与PC和智能手机不同,汽车是科技的集大成者,将电子行业过去几十年发展积累下来的技术,包括应用数据平台、基础计算平台、电子电气架构、成熟可靠的零部件、软件等完全综合起来,这对智能化底座和芯片提出了越来越高的要求。一颗小小的车载芯片,不仅要符合多项行业标准,还要集成CPU+GPU+ISP+NPU神经网络加速器+信号处理等多个复杂功能, Iehesmc
杨宇欣说,传统汽车芯片供应商主要集中在欧、美、日,他们的成长与欧美日汽车企业的成长是密不可分的。但到了智能驾驶阶段,传统汽车芯片厂商在慢慢掉队,那些非汽车领域的芯片巨头,如英伟达、高通、英特尔/Mobileye,他们看到了高性能计算对未来汽车智能化的重要性,反而后来居上;以黑芝麻智能为代表的中国创业公司,一方面在挣扎生存,另一方面也在不断将创新体现在客户的产品中。Iehesmc
在谈及“芯荒”话题时,杨宇欣认为两到三年之内很难有质的改变。原因之一是目前除了中国外,全球汽车MCU所依赖的成熟工艺节点产线都没有扩产计划。尽管国内需求量巨大,许多本土芯片设计企业也正在快速成长,但需要与本土车企互相配合,所以今后几年内“芯荒”问题会有所缓解但不会产生质变。Iehesmc
另一方面,受到地缘政治因素影响,一些车企也开始关注汽车大算力芯片的国产化替代进程。“毕竟头上多了一把刀,况且举刀人也没说这辈子都不会放下”,所以“即使有10%的可能性,也要做好100%的备份”。对汽车行业来说,还是要尽快在国内找到解决方案备份,毕竟在中美技术赛跑过程中,限制只会越来越多。Iehesmc
但汽车芯片非常难做,无论是IP、人才、研发成本都比消费级和工业级芯片高很多;车规芯片从研发到客户认证的产品研发周期很长,需要企业有足够的资金储备、足够的忍耐力和足够强的战略坚定性。数据显示,在量产状态的自动驾驶系统中,国产芯片的比例低于3%。但是,现在汽车芯片给了本土企业很大的机会,加之新的技术迭代使可选范围越来越小,车企不得不选择创新技术公司的产品。为了防止未来出现芯片供应短缺,更需要培养本土供应商。Iehesmc
汽车芯片的大多数关键环节已经有本土供应商,客户已经在用或在开发产品,只是未必都已实现批量上车。在杨宇欣看来,2025年能不能上车非常关键,因为车企一旦投入大量人力、物力培养了一个成熟的供应商,再换到另一家供应商的动力会呈几何级数下降。Iehesmc
算力和算法哪个重要?
尽管不是主动回应Thor芯片带来的行业影响,但杨宇欣在谈及算力和算法话题时表示,“算力是整个系统功能的边际,所以算力更重要。而作为软件的算法有很多可以妥协的方式,所以真正要实现芯片指标,芯片企业的硬件能力是非常重要的。”Iehesmc
他说考虑到车路协同是当前国内很重要的技术路线,因此黑芝麻智能的终端算力平台一方面赋能汽车,让车变得足够聪明、足够智能,另一方面也赋能路的智能化。也就是说,车的感知范围是250-300米,如果路变得智能,就可以无限延伸车的感知距离。当车的感知数据和路的感知数据充分融合,再配合云控平台,例如一些车路协同试点案例,通过动态调节路况就可以将拥堵率降低三分之一以上。作为技术平台的延伸,黑芝麻智能已在国内几个城市开始试点,跟合作伙伴配合实现未来可以期待的自动驾驶落地。Iehesmc
“在追逐大算力过程中,业内开始出现偷换概念的做法,例如用所谓的AI TOPS,或者等效TOPS,来代替实际的客观算力。”黑芝麻智能副总裁丁丁认为,乘加器数量、频率赫兹等指标都可以非常客观的量化芯片的真实算力。但要以等效算力来凑TOPS数值,那就需要牺牲自动驾驶最需要的精度。Iehesmc
“如果单纯为了凑TOPS数值,把8比特计算用4比特来替代,虽然算力可以直接翻倍,但事实上没有任何一个自动驾驶网络按4比特来跑,这样的数值,缺乏科学性及严谨性。”丁丁说。Iehesmc
其次,MobileNET网络主要是手机或消费类应用,模型和功能精度要求与自动驾驶要求相差甚多,不是车厂需要的合理的数据参考。行业共识是用实时感知的高精度ResNET架构搭建自动驾驶算法架构,而以MobileNet对标实际使用的ResNet跑分是非常不公平的事情。Iehesmc
第三,汽车芯片的主要量产节点是16nm,很少有100或200T的芯片。乘加器和工艺决定了芯片大小,如果讲等效算力,芯片是25×25mm,芯片中几十T算力基本占到三分之一面积。从比例上看,芯片就会变成40×40mm,但其实芯片并没有那么大。这证明了在16nm上讲的算力并不真实。Iehesmc
地平线联合创始人&CTO黄畅此前接受包括《国际电子商情》在内的媒体采访时表示,“提升有效算力这条路是没有止境的。”当前,自动/智能驾驶领域行业的基础算力需求是:L2级,10TOPS左右;L2+,几十TOPS;L3,100TOPS以上;L4,1000TOPS以上。Iehesmc
“地平线关注峰值算力的持续提升,但本质上更加关注有效算力的提升。就我个人看来,L2+级最好就能达到百TOPS量级。因为随着全场景自动驾驶的复杂度越来越高,没有足够有效的算力进行处理,将很难满足实际需求。“他说,地平线认为评估一颗AI芯片效能最合理的指标就是FPS/Watt或FPS/$,也就是芯片为了达成AI处理性能所付出的功耗和成本,因此能让软件做的事情尽可能让软件做,硬件做简单、极致、高效且容易被软件灵活调用的功能。Iehesmc
FPS(Frames Per Second)由算法架构决定,也被称之为算法领域的新摩尔定律,大约会在9-14个月的时间内将AI任务需要的计算次数和复杂度降低一半。 Iehesmc
依照这个评估标准,在典型分类模型下,征程5在处理单帧输入的百万像素大图时,其性能达英伟达Xavier的 6.2倍;针对高效模型(EfficientNet)更接近自动驾驶场景的物体检测,同精度下,征程5的性能是Xavier的9倍多,Orin的近3倍;能效比方面,在达到更高性能的条件下,征程5的能效比接近Orin的9倍。Iehesmc
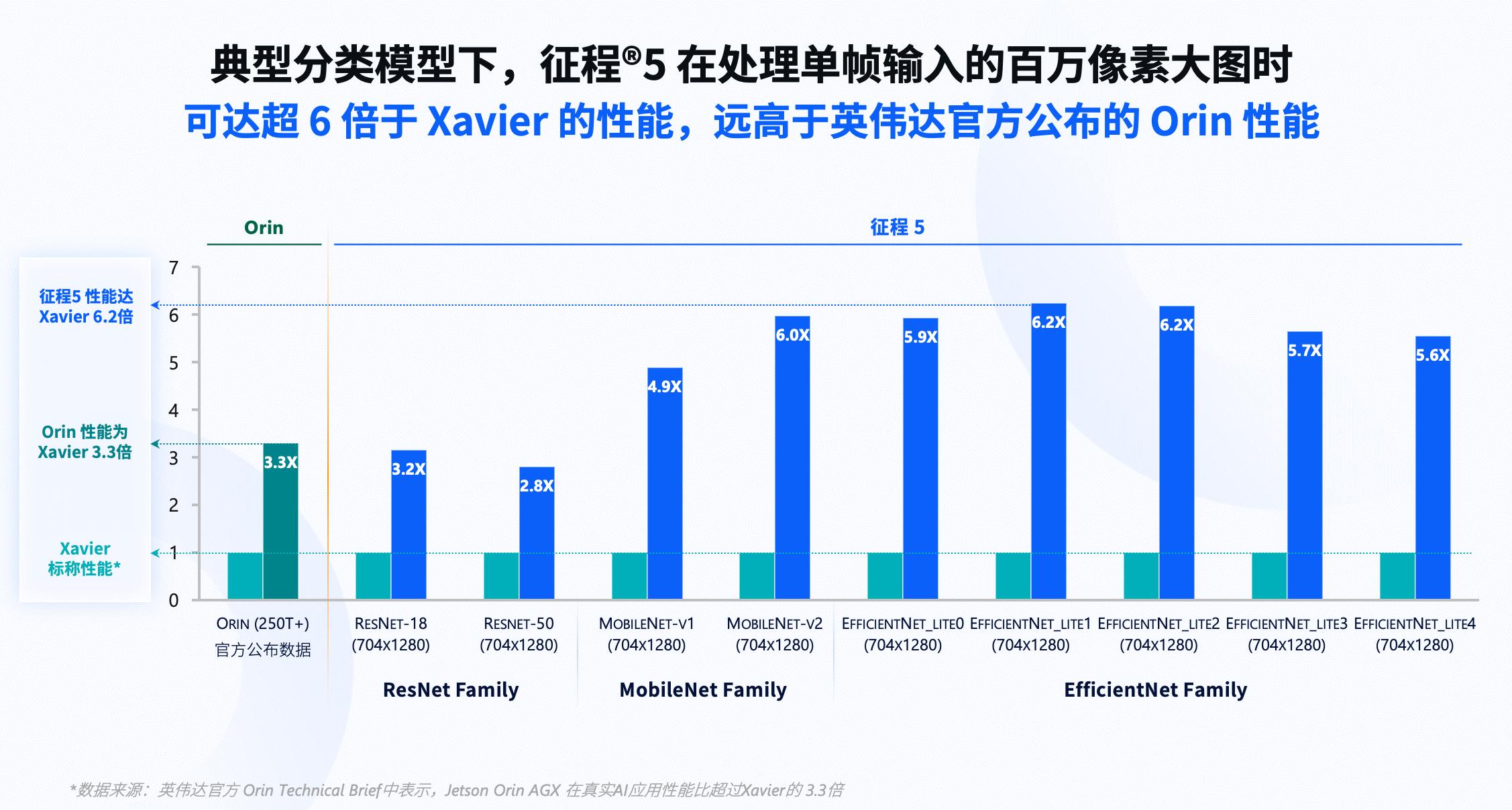 Iehesmc
Iehesmc
中国头部企业前进到了哪里?
黄畅认为,面向未来的自动驾驶算法,支持数据驱动、神经网络模型推理计算的专用芯片占比会显著增加,而CPU这样的处理器的需求量则不会显著增加。他为此提出了这样的观点,即,“加速高等级自动驾驶落地的根本途径,是范式级的智能算法和支持这种算法的硬件体系相结合,也就是我们经常说的软硬结合。”通过软硬协同优化的方式,在首重效能的情况下,地平线打造出兼顾灵活的新一代AI计算架构“贝叶斯”。Iehesmc
“贝叶斯”是地平线实现软硬结合理念的载体,最大特点是高性能、低延迟、低能耗。地平线通过聚焦最新的神经网络架构来服务真实的自动驾驶场景,坚持高度软硬件的并行化和近存计算等举措,最大程度优化内存占有与访存,灵活访问高带宽的存储,确保BPU在非常灵活的条件下提供足够好的算力密度和能效比。Iehesmc
从自动驾驶芯片本身来看,符合ASIL-B产品认证标准的征程5可以称之为是“全面满足高等级自动驾驶量产需求”一款芯片。它具有强大的深度学习计算能力,多样化计算组合、丰富的传感器接口和通讯能力,完全针对自动驾驶场景,满足全车电子电气架构的需求,领先的自动驾驶算法闭环验证。在最接近于量产级的参考设计Matrix 5中,就包括单颗/双颗/4颗“征程5”硬件方案,对应算力从128TOPS到最高512TOPS,Iehesmc
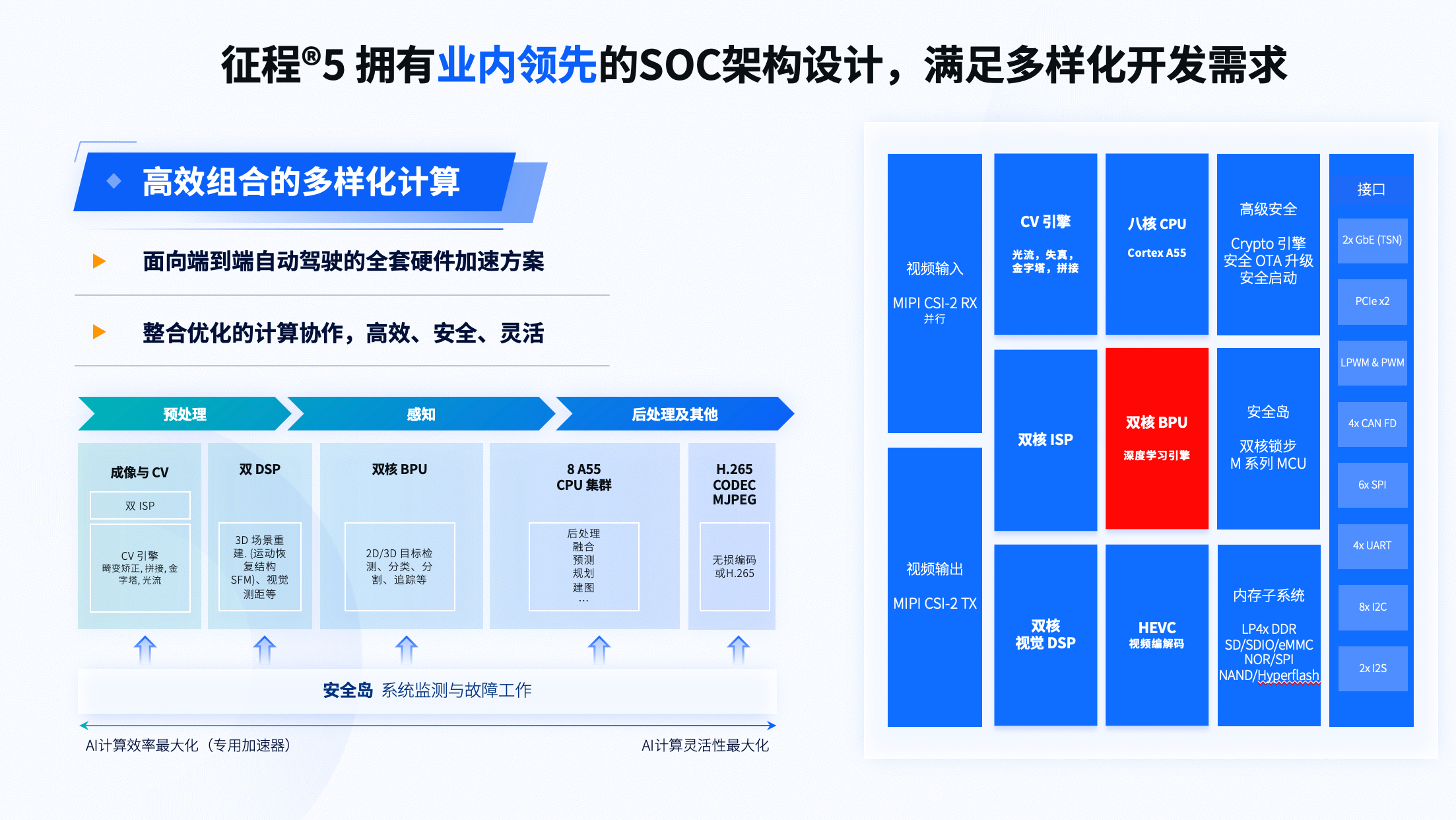 Iehesmc
Iehesmc
杨宇欣不否认英伟达的技术领先性,“确实走在前面”,但黑芝麻2023年将要发布的A2000芯片有望在性能、算力和集成度方面超过Orin。目前的A1000系列是性价比更高的产品,完全能够满足车厂行泊一体主流功能的需求,填补了入门级芯片4T/8T算力与Orin254T算力之间的市场空白。Iehesmc
“未来的芯片技术方向,一种是英伟达GPU架构,另一种就是类似特斯拉、高通、Mobileye,华为走的ASIC技术路线。”杨宇欣表示,GPU是完全开放通用的,面向所有场景都是统一的软硬件架构,这也是自动驾驶产业发展之初,多数车厂选用英伟达的重要原因之一。因为在通用架构的基础上,车厂基于处理器进行软件层面的开发就可以了,操作更加容易。Iehesmc
而黑芝麻之所以更看好ASIC专用芯片,就是因为此类芯片专门面向驾驶相关主流的网络、模型、算子进行开发,面积更小,成本更低,功耗更小。但这并不意味着要对不同车型开发和验证不同的ASIC芯片,总体来说,不同车型需要实现的功能大致相同,而且芯片面对模型和算子进行有限开放,算法快速迭代不会影响到芯片对上层功能的支持。从黑芝麻的角度来讲,除了要考虑架构演进、芯片高集成度之外,同时也还要顾及中国市场和客户对性价比的要求。Iehesmc
目前,黑芝麻智能的A1000和A1000L正处在量产状态,前者能够支持入门级的行泊一体,后者可以支持9V5R或者10V5R,两款平台化方案基本能够覆盖到市面上几乎所有的渗透率比较高的自动驾驶辅助和自动驾驶功能,包括Drive N/Drive S/Drive B,乃至下一代计算平台Drive T。黑芝麻希望以平台化的矩阵,构建一个Drive BEST的平台,达到自动驾驶更高的成绩。Iehesmc

-
微信扫一扫,一键转发
-

关注“国际电子商情” 微信公众号
- 上市分销商2024年度业绩快报抢先看
2024年,6家上市分销商中有3家实现归母净利润同比增长。
- Q1财测大降25%,安森美称将“精简”业务
在全球半导体行业面临增长放缓的背景下,安森美(onsemi)在2024年第四季度业绩下滑,并预计2025年第一季度营收将大幅下降。为应对市场挑战,公司宣布将采取“精简”业务等措施以提升竞争力……
- 计划融资超40亿,哪吒汽车等待“复活”
工厂正待复产……
- 巴黎AI峰会现分歧:联合声明遇冷,“空谈”质疑待解
当地时间2月10 - 11日,由法国、印度联合主办的人工智能行动峰会(AI Action Summit)在巴黎大皇宫隆重举行。
- 汽车巨头紧急呼吁重启美国50亿美元充电计划:仅建126个
美国50亿美元的电动汽车充电计划陷入停滞,仅建成126个充电桩。汽车巨头们终于坐不住了,紧急呼吁政府重启这一关键项目……
- 雷诺重启与富士康谈判,拟出售日产股份
在汽车行业智能化与电动化浪潮的冲击下,传统汽车巨头纷纷寻求战略转型与资本布局的优化……
- 2024年全球手机销量前十榜单公布,谁是全球销量冠军?
近日市场研究机构Counterpoint Research和Canalys均发布了2024年全球销量前十的手机榜单。虽然其中有部分机型或者排名不同,但这两份榜单均仅有苹果和三星两大品牌入选……
- 半导体市场增长强劲,2024年销售额首破6000亿美元大关
国际电子商情10日讯 最新数据显示,2024年全球半导体行业迎来了历史性突破,销售额首次突破6000亿美元大关,达到6276亿美元,同比增长19.1%……
- 长安、东风汽车同日宣布重组,市场猜测可能合并
2月9日晚,中国兵器装备集团有限公司(简称“兵器装备集团”)旗下长安汽车、长城军工、建设工业等上市公司发布通告,透露接到兵器装备集团的通知,集团正在与其他国资央企筹划重组事宜。同日,东风汽车集团有限公司(简称“东风公司”)旗下的东风股份、东风科技也宣布,东风公司正在探讨与其他国资央企的重组可能性。
- 豪掷180亿韩元,韩国计划投资MicroLED
国际电子商情8日讯 韩国正加速布局下一代显示技术,计划投资180亿韩元推动MicroLED等技术研发,以巩固其全球市场地位。
- 韩国芯片巨头Magnachip寻求再次出售,LX集团或成最大赢
国际电子商情8日讯 在显示器行业长期低迷的背景下,曾因美国干预而搁置出售计划的韩国芯片制造商Magnachip,在时隔数年后再度寻求出售……
- 软银65亿美元收购Ampere谈判进入尾声,最快本月官宣
国际电子商情8日讯 软银集团(SoftBank)以65亿美元(含债务)估值对美国芯片设计公司Ampere Computing LLC的收购交易接近达成,最快可能在本月官宣。交易若最终完成,将成为2025年全球半导体行业最具标志性的并购事件之一……
- 全球半导体设备市场,方兴未艾!
近日,Tokyo Electron(以下简称“TEL”)宣布,将在日本宫城县建造一座新的生产大楼,由TEL的制造子公司TEL宫城公司
- 中国北大研究团队,氮化镓技术获新进展
近日,北京大学物理学院杨学林、沈波团队,联合宽禁带半导体研究中心等多个科研机构,在氮化镓外延薄膜中位错的原
- 2025年数据中心五大趋势
数据中心/云计算可以说是人工智能领域的核心,占据了英伟达总收入的85%~90%。
- 重庆发布新政,聚焦高端芯片与器件发展
近日,重庆市人民政府办公厅印发《重庆市推动经济持续向上向好若干政策举措》,提出支持科技领军企业、产业链龙
- 消息称苹果取消Mac连接AR眼镜,独立AR眼镜研发仍推进中
2月10日消息,据彭博社记者马克·古尔曼报道,苹果公司取消了一款与Mac连接使用的AR眼镜项目,但仍在积极推进独立
- 三星2nmSF2工艺试产良率约30%?
韩国媒体TheBell报道,三星正在为旗下自研处理器Exynos2600投入大量资源,以确保其按时量产。
- 2024年Q4平板电脑市场整体增长放缓,iPad占据40%市场份额
尽管全球平板电脑市场在2024年的大部分时间都保持着两位数的增长,但在2024年Q4,平板电脑出货量仅同比增长3%。
- AR微显示厂商Cellid完成1300万美元融资
2月7日,日本AR眼镜光学厂商Cellid宣布,公司通过定向增发完成总额1300万美元(约人民币9478.95万元)的融资。
- 多家半导体大厂官宣换帅!
近日,多家媒体发布消息称,瑞芯微前副总经理陈锋将出任Arm在中国的合资公司安谋科技首席执行官(CEO)一职。
- 全球半导体厂商营收10强排行榜出炉!
美国市场研究机构Gartner发布2024年全球半导体厂商营收排行榜。
- 2024年先进封装晶圆占比近半
随着传统扩展方式的成本和复杂性上升,先进封装已成为满足人工智能(尤其是大型语言模型训练)性能需求的一种方式
- 2024年AIPC未能提振笔电市场,仅从2023年的低点温和增长5%
2024年Q4,全球笔记本电脑出货量同比增长了6%,达到5450万台。
- 英飞凌在泰国新建后道工厂,优化和丰富生产布局
英飞凌位于曼谷南部沙没巴干府的新后道厂破土动工,该厂将扩大公司在亚洲的生产布局。
- 芯耀辉:从传统IP到IP2.0,AI时代国产IP机遇与挑战齐飞
2024年,集成电路行业在变革与机遇中持续发展。面对全球经济的新常态、技术创新的加速以及市场需求的不断变化
- 艾睿电子与印尼初创协会合作,支持本地科技初创公司
雅加达,印尼- 2025年1月14日 - 全球技术解决方案供应商艾睿电子(Arrow Electronics)与印尼初创协会合作(STARFIN
- 【凯新达科技】新年欢聚,共绘年会精彩篇章!
无畏挑战 共创未来祥龙回首留胜景,金蛇起舞贺新程。在2025年元旦新年之际,深圳市凯新达科技有限公司(以下简
- CES 2025新品:摩尔斯微电子推出Wi-Fi芯片MM8108
最新Wi-Fi HaLow片上系统(SoC)为物联网的性能、效率、安全性与多功能性设立新标准;
配套USB网关,轻松实现Wi- - ST与彭水共绘可持续发展新篇章
随着与三安光电的碳化硅合资工厂落地重庆,2024年6月,意法半导体与重庆市彭水自治县同步启动了可持续发展合作
- 【凯新达科技】2025年度旅游活动景点精彩报道
凯新达科技 自由之旅 征途同行
- 超高性价比AI电脑:英伟达NVIDIA Jetson Orin Nano Super真香!iCEas
NVIDIA Jetson Orin™ Nano Super 开发者套件是一款尺寸小巧且性能强大的超级计算机,重新定义了小型边
- TI推出新一代支持边缘AI的雷达传感器和汽车音频处理器,改进车内驾
德州仪器今日推出了全新的集成式汽车芯片,能够帮助各个价位车辆的驾乘人员,实现更安全、更具沉浸感的驾驶体验
- 【原厂入驻】飞虹半导体现已入驻iCEasy商城!
广州飞虹半导体科技有限公司成立于广州越秀区,诚信经营20多年。主要研发、生产、经营:场效应管、三极管等半
- 携手共进,江波龙与电子五所在中山展开深度交流
近日,半导体存储品牌企业江波龙与工业和信息化部电子第五研究所(中国赛宝实验室,以下简称“电子五所”)在江波龙
- 【原厂入驻】迈巨微电子现已入驻iCEasy商城!
深圳迈巨微电子有限公司深耕锂电池管理芯片领域,围绕电池健康和安全,电池电量计算二个核心技术能力,提供完善的